
Partial Git Clones
/ 10 min read
Table of Contents
I was recently tasked with auto scaling the disk associated with VM that we make use of for crawling git repositories and indexing the code files as it otherwise needed manual intervention to increase the size whenever there was no space left on disk.
However, I took a step back to find ways on saving disk space and improving crawl times instead of just doing autoscaling because I had briefly read about the existence of such cloning techniques.
This took me down the rabbit hole of sparse git clones, the caveats associated with them, reading through the RFC and a journey of finally making it work.
So, in this article I intend to share details on what are sparse clones and details associated with their working. Let’s begin with understanding how we used to crawl git metadata prior to my changes.
Existing Algorithm
For indexing the contents present in the code repositories we want to gather following details:
- create and update time for code files
- files or directories that were deleted
- oldest and latest commit associated with each file
- contents of code files
Above all content and metadata is needed for developing complete context of the code repositories. The older flow used to look as below for each repository:
%3bfill:%23ECECFF%3b%7d%23mermaid-0 text.actor%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .actor-line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-0 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-0 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-0 %23arrowhead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .sequenceNumber%7bfill:white%3b%7d%23mermaid-0 %23sequencenumber%7bfill:%23333%3b%7d%23mermaid-0 %23crosshead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .labelBox%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-0 .labelText%2c%23mermaid-0 .labelText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .loopText%2c%23mermaid-0 .loopText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-0 .note%7bstroke:%23aaaa33%3bfill:%23fff5ad%3b%7d%23mermaid-0 .noteText%2c%23mermaid-0 .noteText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-0 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23ECECFF%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-0 .actor-man line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-0 .actor-man circle%2c%23mermaid-0 line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3bstroke-width:2px%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol height='24' width='24' id='computer'%3e%3cpath d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol clip-rule='evenodd' fill-rule='evenodd' id='database'%3e%3cpath d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol height='24' width='24' id='clock'%3e%3cpath d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto-start-reverse' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='7.9' id='arrowhead'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker refY='4.5' refX='4' orient='auto' markerHeight='8' markerWidth='15' id='crosshead'%3e%3cpath style='stroke-dasharray: 0%2c 0%3b' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' stroke-width='1pt' stroke='black' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='15.5' id='filled-head'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='40' markerWidth='60' refY='15' refX='15' id='sequencenumber'%3e%3ccircle r='6' cy='15' cx='15'/%3e%3c/marker%3e%3c/defs%3e%3cg%3e%3cline class='loopLine' y2='119' x2='353' y1='119' x1='64'/%3e%3cline class='loopLine' y2='254' x2='353' y1='119' x1='353'/%3e%3cline class='loopLine' y2='254' x2='353' y1='254' x1='64'/%3e%3cline class='loopLine' y2='254' x2='64' y1='119' x1='64'/%3e%3cpolygon class='labelBox' points='64%2c119 114%2c119 114%2c132 105.6%2c139 64%2c139'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' class='labelText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='132' x='89'%3eloop%3c/text%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' class='loopText' text-anchor='middle' y='137' x='233.5'%3e%3ctspan x='233.5'%3e%5bPoll until complete%5d%3c/tspan%3e%3c/text%3e%3c/g%3e%3cg%3e%3cline class='loopLine' y2='352' x2='353' y1='352' x1='64'/%3e%3cline class='loopLine' y2='487' x2='353' y1='352' x1='353'/%3e%3cline class='loopLine' y2='487' x2='353' y1='487' x1='64'/%3e%3cline class='loopLine' y2='487' x2='64' y1='352' x1='64'/%3e%3cpolygon class='labelBox' points='64%2c352 114%2c352 114%2c365 105.6%2c372 64%2c372'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' class='labelText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='365' x='89'%3eloop%3c/text%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' class='loopText' text-anchor='middle' y='370' x='233.5'%3e%3ctspan x='233.5'%3e%5bPoll until complete%5d%3c/tspan%3e%3c/text%3e%3c/g%3e%3cg%3e%3cline class='loopLine' y2='1071' x2='353' y1='1071' x1='64'/%3e%3cline class='loopLine' y2='1298' x2='353' y1='1071' x1='353'/%3e%3cline class='loopLine' y2='1298' x2='353' y1='1298' x1='64'/%3e%3cline class='loopLine' y2='1298' x2='64' y1='1071' x1='64'/%3e%3cline style='stroke-dasharray: 3%2c 3%3b' class='loopLine' y2='1165' x2='353' y1='1165' x1='64'/%3e%3cline style='stroke-dasharray: 3%2c 3%3b' class='loopLine' y2='1234' x2='353' y1='1234' x1='64'/%3e%3cpolygon class='labelBox' points='64%2c1071 114%2c1071 114%2c1084 105.6%2c1091 64%2c1091'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' class='labelText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='1084' x='89'%3epar%3c/text%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' class='loopText' text-anchor='middle' y='1089' x='233.5'%3e%3ctspan x='233.5'%3e%5bFile Content Fetching%5d%3c/tspan%3e%3c/text%3e%3c/g%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='80' x='207'%3eClone repository%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='109' x2='338' y1='109' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='169' x='207'%3eCheck clone status%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='198' x2='338' y1='198' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='213' x='210'%3eIN_PROGRESS/SUCCESS%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='244' x2='79' y1='244' x1='341'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='269' x='207'%3eWrite logs%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='298' x2='338' y1='298' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='313' x='454'%3eUpload Logs%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='342' x2='564' y1='342' x1='343'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='402' x='207'%3eCheck write logs status%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='431' x2='338' y1='431' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='446' x='210'%3eIN_PROGRESS/SUCCESS%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='477' x2='79' y1='477' x1='341'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='502' x='207'%3eDirectory Diff%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='531' x2='338' y1='531' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='546' x='454'%3eUpload Directory Diff%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='575' x2='564' y1='575' x1='343'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='590' x='210'%3eSUCCESS%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='619' x2='79' y1='619' x1='341'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='634' x='207'%3eWrite Files at HEAD%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='663' x2='338' y1='663' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='678' x='454'%3eUpload Files at HEAD%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='707' x2='564' y1='707' x1='343'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='722' x='210'%3eSUCCESS%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='751' x2='79' y1='751' x1='341'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='766' x='76'%3eParse Directory Diff%3c/text%3e%3cpath style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' d='M 76%2c795 C 136%2c785 136%2c825 76%2c815'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='840' x='320'%3eCreate/Delete Directories%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='869' x2='564' y1='869' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='884' x='76'%3eParse Files at HEAD%3c/text%3e%3cpath style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' d='M 76%2c913 C 136%2c903 136%2c943 76%2c933'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='958' x='76'%3eParse Logs%3c/text%3e%3cpath style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' d='M 76%2c987 C 136%2c977 136%2c1017 76%2c1007'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='1032' x='320'%3eCreate/Delete/Update Files%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='1061' x2='564' y1='1061' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='1121' x='207'%3eGet file 1%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='1150' x2='338' y1='1150' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='1190' x='207'%3eGet file 2%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='1219' x2='338' y1='1219' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='1259' x='207'%3eGet file N%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='1288' x2='338' y1='1288' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='1313' x='210'%3eFile contents%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='1342' x2='79' y1='1342' x1='341'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='1357' x='320'%3eCreate content docs%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='1386' x2='564' y1='1386' x1='76'/%3e%3c/svg%3e)
Git Commands
For each of the above tasks the associated git commands look as follows:
| Task | Git Command |
|---|---|
| Clone | git clone |
| Write Logs | git log -c —name-status —diff-filter=‘AMRD’ |
| Write Directories | git ls-tree -d -r —name-only HEAD |
| Diff Directories | diff $OLD_HEAD_DIRS $NEW_HEAD_DIRS |
| Write Files at HEAD | git ls-tree -r —name-only HEAD |
The additional parameters in git log command serve the following purposes:
-c: Produce combined diff output for merge commits where conflict resolution was required.--name-status: Adds detail about whether a file was modified, renamed, added or deleted--diff-filter='AMRD': Provides details about only particular kind of change in output
The ls-tree command is used to list the files and directories in git the flags are for the following reason:
-r: recurse into sub directory instead of just limiting to the present directory-d: show only directories--name-only: show path of file or directory without object type
Without -d and with -r we get all the files in repository.
Before proceeding with the optimizations in the current flow we need to get some basic understanding of how git organizes it’s data.
Data Organization
Git organizes the historical data we have in our files and directories into following entities:
- tree (directory -> triangle)
- blob (file -> squares)
- commitish (commit, branch, tag, etc -> circles)
The time flows from left to right in below diagram.
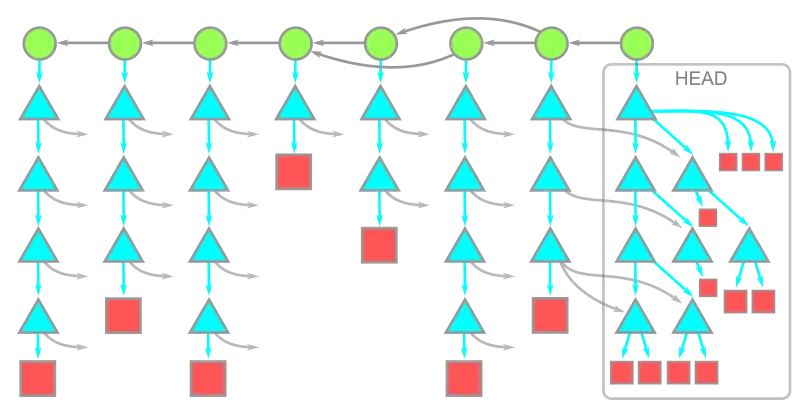
When we execute a git clone, the client requests data from server (git forge) for all the latest commits and then every tree and blob associated with these commits are also fetched.
With an increasing amount of code in age of LLMs git histories and transitively the amount of blobs and trees that are present in repositories are increasing at an exponential rate.
Partial and Shallow Clones
There can be different scenarios of what data we need while cloning:
- We just need the
HEADand it’s associated trees and blobs but no history - We only need the blobs at
HEADbut trees from complete history - We only need blobs and tress at
HEADbut complete history
For the above cited scenarios where we don’t care about the full data for repository, we can use partial or shallow clones which are more suited and efficient option.
Partial clone feature is accessible using the --filter argument with clone command. The full list of filter options exist in the git rev-list documentation.
There are two specific kinds of clone that we can make use of for the above cited cases.
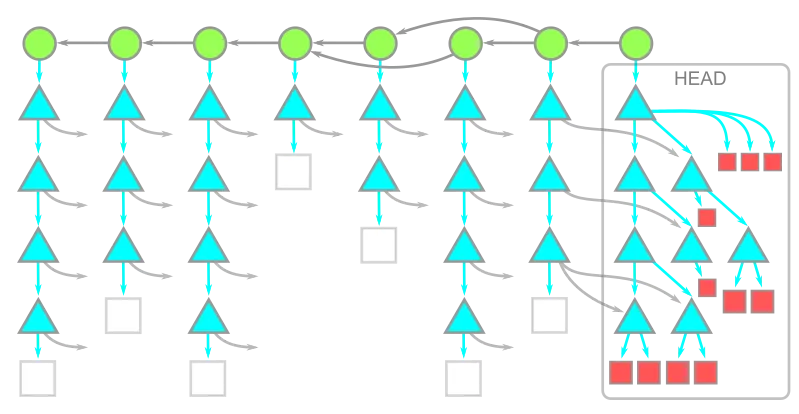
Blobs at HEAD
We only need the blobs at HEAD along trees from complete history.
git clone --filter=blob:noneBelow is how the git repository storage will look like
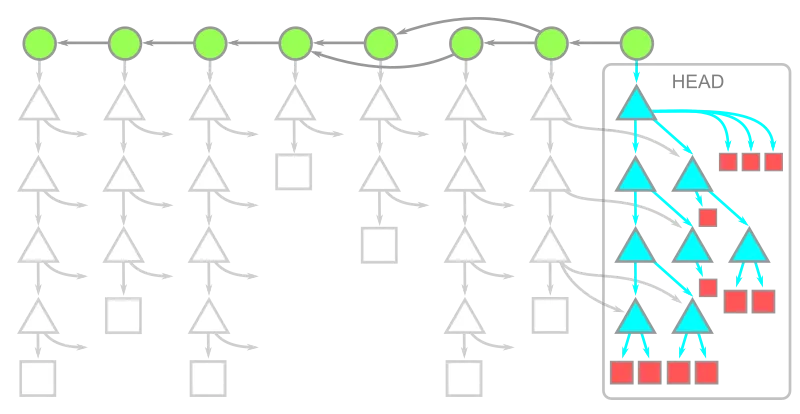
Trees at HEAD
We only need the blobs and trees at HEAD along with the complete history.
git clone --filter=tree:noneBelow is how the git repository storage will look like
Only HEAD
In case of CI/CD throw away environments we can make use of shallow clones. They only provide the data at HEAD and no commit history is provided.
git clone --depth=1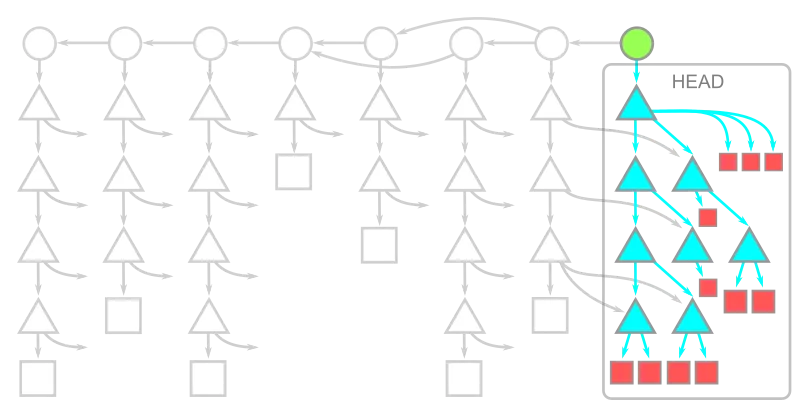
Coming back to the optimization for our crawls both treeless and blobless are good options but just to not be too aggressive we went ahead with blobless clones. In case you want to read about caveats of the other options checkout this deep dive blog from Github.
Promisor Remotes
The first issue we had with blobless clones was around auth failure in fetching missing blobs while doing a pull from promisor remote.
The authorization mechanism we use for git operations is OAuth token. The complete command for pull is as below
git pull https://x-access-token:$TOKEN@github.com/random-github-org/some-repo.gitThe issue which chatgpt helped me figure out was that the adhoc url we were providing for fetching content doesn’t set the promisor remote. I read through the cited source it had found which was the specification for blobless clone.
So, I made the change to always set the origin remote before starting a pull operation so that a fresh token is in place as the one set during clone might have expired already.
git remote set-url origin https://x-access-token:$TOKEN@github.com/random-github-org/some-repo.git && git pull originRename Detection
The second critical error we saw was during git log where the command was first failing with the same error as git pull about unauthenticated promisor remote. So, I did the same for git log also where we first update the promisor with latest token and the try logging.
Even with this we were still failures occurring which talked about repository corruption. Below is a similar error that occurs if we try to clone tigerbeetle with blobless clone and then storing complete logs.
git clone --filter=blob:none --single-branch https://github.com/tigerbeetle/tigerbeetlegit log -c --name-status > log.txt
fatal: You are attempting to fetch f9c4c763962287ec59d5fa4aa112c6a029aae3df, which is in the commit graph file but not in the object database.This is probably due to repo corruption.If you are attempting to repair this repo corruption by refetching the missing object, use 'git fetch --refetch' with the missing object.fatal: could not fetch 08bfee5769fcac65acf77ee074c27c79b03aa8b0 from promisor remoteThe inability to find the right solution was already leaning me into losing blobless clone and reverting to full clones. I found some git mailing list threads which described similar issue but no resolution.
I wanted a final go. So, I tried taking help from my pair debugger, chatgpt. I gave it the full context of what we were trying to do and how our crawls work.
It provided me insights that git needs to traverse the whole tree for rename detection of files. This made absolute sense imagine a scenario as below
%3btext-align:center%3b%7d%23mermaid-1 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-1 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-1 .cluster text%7bfill:%23333%3b%7d%23mermaid-1 .cluster span%7bcolor:%23333%3b%7d%23mermaid-1 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-1 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-1 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-1 .icon-shape%2c%23mermaid-1 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-1 .icon-shape p%2c%23mermaid-1 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-1 .icon-shape rect%2c%23mermaid-1 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-1 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-1_flowchart-v2-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-1_flowchart-v2-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-1_flowchart-v2-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-1_flowchart-v2-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-1_flowchart-v2-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-1_flowchart-v2-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_b1_m_0' d='M396.688%2c52.414L400.854%2c52.414C405.021%2c52.414%2c413.354%2c52.414%2c423.138%2c59.366C432.921%2c66.319%2c444.154%2c80.223%2c449.771%2c87.175L455.388%2c94.128'/%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_a1_m_0' d='M394.461%2c189.016L398.999%2c189.016C403.536%2c189.016%2c412.612%2c189.016%2c422.766%2c182.063C432.921%2c175.111%2c444.154%2c161.207%2c449.771%2c154.254L455.388%2c147.302'/%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_a2_a1_0' d='M105.851%2c156.627L112.214%2c162.025C118.578%2c167.424%2c131.304%2c178.22%2c149.237%2c183.618C167.169%2c189.016%2c190.307%2c189.016%2c213.445%2c189.016C236.583%2c189.016%2c259.721%2c189.016%2c275.161%2c189.016C290.602%2c189.016%2c298.344%2c189.016%2c302.215%2c189.016L306.086%2c189.016'/%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_b2_b1_0' d='M257.859%2c52.414L262.026%2c52.414C266.193%2c52.414%2c274.526%2c52.414%2c282.193%2c52.414C289.859%2c52.414%2c296.859%2c52.414%2c300.359%2c52.414L303.859%2c52.414'/%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_a2_b2_0' d='M105.851%2c84.802L112.214%2c79.404C118.578%2c74.006%2c131.304%2c63.21%2c141.168%2c57.812C151.031%2c52.414%2c158.031%2c52.414%2c161.531%2c52.414L165.031%2c52.414'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(352.2734375%2c 52.4140625)' id='flowchart-b1-0' class='node default'%3e%3ccircle cy='0' cx='0' r='44.4140625' style='' class='basic label-container'/%3e%3cg transform='translate(-36.9140625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='73.828125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eRename 2%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(476.8671875%2c 120.71484375)' id='flowchart-m-1' class='node default'%3e%3ccircle cy='0' cx='0' r='30.1796875' style='' class='basic label-container'/%3e%3cg transform='translate(-22.6796875%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='45.359375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eMerge%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(352.2734375%2c 189.015625)' id='flowchart-a1-2' class='node default'%3e%3ccircle cy='0' cx='0' r='42.1875' style='' class='basic label-container'/%3e%3cg transform='translate(-34.6875%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='69.375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eUnrelated%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(63.515625%2c 120.71484375)' id='flowchart-a2-4' class='node default'%3e%3ccircle cy='0' cx='0' r='55.515625' style='' class='basic label-container'/%3e%3cg transform='translate(-48.015625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='96.03125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eBase Commit%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(213.4453125%2c 52.4140625)' id='flowchart-b2-6' class='node default'%3e%3ccircle cy='0' cx='0' r='44.4140625' style='' class='basic label-container'/%3e%3cg transform='translate(-36.9140625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='73.828125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eRename 1%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
The final merge commit has a renamed file but to find what the actual file name was git will need to follow the commits that were there in a branch which isn’t default. So git will need on demand blob fetches for rename detection.
In our code though we treat renames as a separate delete and add. This same thing can be achieved using git where we ask it to not bother with rename detection using --no-renames.
git log -c --name-status --no-renames --diff-filter='AMD'For renamed files git now show in output that original file was deleted and a new file was added to the repository.
Verdict
The disk usage reduction we get with blobless clone range from 2x upto 10x depending on the branching and size of repository.
| Repository | Full Clone | Blobless Clone |
|---|---|---|
| Kubernetes | 1.5G | 575M |
| Tigerbeetle | 40M | 21M |
| Bitcoin Core | 365M | 132M |
| Signal Android | 2G | 193M |
| Zed | 384M | 135M |
| Glean | 8.1G | 2.2G |
Apart from disk usage savings there was also time savings given clones are much faster now, with speedup ranging from 1.4x upto 20x
| Repository | Full Clone Time (s) | Blobless Clone Time (s) |
|---|---|---|
| Kubernetes | 280.1 | 64.1 |
| Tigerbeetle | 5.9 | 4.2 |
| Bitcoin Core | 88s | 24.6 |
| Signal Android | 390.1 | 18.9 |
| Zed | 84.2 | 15.6 |
| Glean | 884 | 215.3 |
The no rename detection feature that we added doesn’t provide much speed up as compared to base scenario of full clone because in full clone it’s very easy to traverse the whole repository given everything has already been downloaded and indexed in the commit-graph.
The cost of logging only comes in blobless clone where every on demand blob needs a network request to the git forge which is more expensive than traversing locally stored files.
Conclusion
With these optimizations in place I finally went ahead and also created a health check that takes care of auto scaling disk so no manual intervention by engineers is required.
The first version of any software in 90% of the cases is built just with getting a MVP out so there is always possibility of new innovations and engineering improvements, the only question to answer is..
For us Harvesters at Glean the major metric is crawl times and cost savings which were both heavily improved with my changes.
The primary reason I was aware about existence of partial and shallow clones is because I enjoy reading technical blogs.
The knowledge we accumulate might not come in handy right away but someday it might.
Another thing to note in my journey is that LLMs with all the data they are trained on are amazing as debuggers. They saved me from reverting the feature when my google searches were failing to provide any help.
It’s important though that we should do those manual searches and engage with LLM citations because it was the random information that we accumulate while searching that builds the mental model and connections.

Thanks for reading you can read more such articles on my blog.
Photo by Lachlan Gowen on Unsplash