
Rate Limiting
/ 6 min read
Table of Contents
Why to Rate Limit?
Rate Limiting is a crucial part of designing any API it maybe private or public. A rate limiter caps how many requests a sender can issue in a specific window of time. A rate limiter provides following features:
- Defense against a Denial of Service from malicious actors trying to pull down the service.
- Ensures the load on servers is always under maintainable state by discarding too many requests.
- Prevent broke developers from receiving an unexpectedly large bill in today’s auto scalable cloud service offerings.
 I can relate with you Max :‘(
I can relate with you Max :‘(
Algorithms
Rate Limiting implementation can use different algorithms based on the requirement of our applications. Two key parameters are how we define our user (ip address, user id, device, etc.) and the second being our time window (1 minute, 1 hour, etc.)
Token Bucket
In token bucket algorithm we have a fixed size bucket which keeps getting filled by tokens at a uniform rate. When a new request arrives it is only processed if we have at-least one token in the bucket, otherwise the request is dropped.
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape rect%2c%23mermaid-0 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_r_c_0' d='M200.844%2c45.425L205.01%2c45.425C209.177%2c45.425%2c217.51%2c45.425%2c230.322%2c50.997C243.133%2c56.568%2c260.422%2c67.71%2c269.067%2c73.281L277.711%2c78.853'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_t_b_0' d='M61.75%2c155.114L65.833%2c155.03C69.917%2c154.947%2c78.083%2c154.78%2c87.806%2c154.697C97.529%2c154.614%2c108.807%2c154.614%2c114.447%2c154.614L120.086%2c154.614'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' marker-start='url(%23mermaid-0_flowchart-v2-pointStart)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_b_c_0' d='M192.008%2c154.614L197.647%2c154.614C203.286%2c154.614%2c214.565%2c154.614%2c228.844%2c149.202C243.124%2c143.79%2c260.404%2c132.966%2c269.044%2c127.555L277.684%2c122.143'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_c_p_0' d='M347.258%2c81.02L358.219%2c74.916C369.18%2c68.813%2c391.102%2c56.605%2c408.379%2c50.502C425.656%2c44.398%2c438.289%2c44.398%2c444.605%2c44.398L450.922%2c44.398'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_c_d_0' d='M347.258%2c120.02L358.219%2c125.956C369.18%2c131.893%2c391.102%2c143.767%2c410.305%2c149.704C429.508%2c155.641%2c445.992%2c155.641%2c454.234%2c155.641L462.477%2c155.641'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(413.0234375%2c 44.3984375)' class='edgeLabel'%3e%3cg transform='translate(-13.7890625%2c -12)' class='label'%3e%3cforeignObject height='24' width='27.578125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3etrue%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(413.0234375%2c 155.640625)' class='edgeLabel'%3e%3cg transform='translate(-16.8984375%2c -12)' class='label'%3e%3cforeignObject height='24' width='33.796875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3efalse%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(156.046875%2c 45.425453186035156)' id='flowchart-r-0' class='node default'%3e%3crect height='54' width='89.59375' y='-27' x='-44.796875' ry='5' rx='5' style='' class='basic label-container'/%3e%3cg transform='translate(-29.796875%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='59.59375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eRequest%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(34.625%2c 154.61360931396484)' id='flowchart-t-1' class='node default'%3e%3cpolygon transform='translate(-18.625%2c19.5)' class='label-container' points='0%2c0 37.25%2c0 37.25%2c-39 0%2c-39 0%2c0 -8%2c0 45.25%2c0 45.25%2c-39 -8%2c-39 -8%2c0'/%3e%3cg transform='translate(-11.125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='22.25'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3etap%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(156.046875%2c 154.61360931396484)' id='flowchart-b-2' class='node default'%3e%3cpath transform='translate(-31.9609375%2c -32.188156480026464)' style='' class='basic label-container' d='M0%2c8.45877098668431 a31.9609375%2c8.45877098668431 0%2c0%2c0 63.921875%2c0 a31.9609375%2c8.45877098668431 0%2c0%2c0 -63.921875%2c0 l0%2c47.458770986684314 a31.9609375%2c8.45877098668431 0%2c0%2c0 63.921875%2c0 l0%2c-47.458770986684314'/%3e%3cg transform='translate(-24.4609375%2c -2)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='48.921875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eBucket%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(310.984375%2c 100.01953125)' id='flowchart-c-3' class='node default'%3e%3cpolygon transform='translate(-40.640625%2c19.5)' class='label-container' points='-19.5%2c0 81.28125%2c0 100.78125%2c-39 0%2c-39'/%3e%3cg transform='translate(-33.140625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='66.28125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3ecount %26gt%3b 0%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(491.3203125%2c 44.3984375)' id='flowchart-p-4' class='node default'%3e%3ccircle cy='0' cx='0' r='36.3984375' style='' class='basic label-container'/%3e%3cg transform='translate(-28.8984375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='57.796875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eProcess%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(491.3203125%2c 155.640625)' id='flowchart-d-5' class='node default'%3e%3ccircle cy='0' cx='0' r='24.84375' style='' class='basic label-container'/%3e%3cg transform='translate(-17.34375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='34.6875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eDrop%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Leaky Bucket
In leaky bucket algorithm there is a fixed size queue where new requests are queued. These requests are then consumed at a uniform rate. A new request is dropped if bucket is a it’s capacity.
%3btext-align:center%3b%7d%23mermaid-1 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-1 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-1 .cluster text%7bfill:%23333%3b%7d%23mermaid-1 .cluster span%7bcolor:%23333%3b%7d%23mermaid-1 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-1 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-1 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-1 .icon-shape%2c%23mermaid-1 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-1 .icon-shape p%2c%23mermaid-1 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-1 .icon-shape rect%2c%23mermaid-1 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-1 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-1 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-1_flowchart-v2-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-1_flowchart-v2-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-1_flowchart-v2-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-1_flowchart-v2-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-1_flowchart-v2-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-1_flowchart-v2-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_r_c_0' d='M97.594%2c96.31L101.76%2c96.31C105.927%2c96.31%2c114.26%2c96.31%2c123.635%2c96.384C133.011%2c96.458%2c143.427%2c96.605%2c148.636%2c96.679L153.844%2c96.753'/%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_c_b_0' d='M261.425%2c77.31L273.257%2c71.677C285.088%2c66.045%2c308.751%2c54.78%2c326.899%2c49.148C345.047%2c43.516%2c357.68%2c43.516%2c363.996%2c43.516L370.313%2c43.516'/%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_c_d_0' d='M261.425%2c116.31L273.257%2c121.775C285.088%2c127.241%2c308.751%2c138.173%2c328.234%2c143.638C347.716%2c149.104%2c363.018%2c149.104%2c370.669%2c149.104L378.32%2c149.104'/%3e%3cpath marker-end='url(%23mermaid-1_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_b_p_0' d='M437.359%2c43.516L441.526%2c43.516C445.693%2c43.516%2c454.026%2c43.516%2c461.693%2c43.516C469.359%2c43.516%2c476.359%2c43.516%2c479.859%2c43.516L483.359%2c43.516'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(332.4140625%2c 43.515625)' class='edgeLabel'%3e%3cg transform='translate(-13.7890625%2c -12)' class='label'%3e%3cforeignObject height='24' width='27.578125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3etrue%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(332.4140625%2c 149.10395431518555)' class='edgeLabel'%3e%3cg transform='translate(-16.8984375%2c -12)' class='label'%3e%3cforeignObject height='24' width='33.796875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3efalse%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(52.796875%2c 96.30978965759277)' id='flowchart-r-0' class='node default'%3e%3crect height='54' width='89.59375' y='-27' x='-44.796875' ry='5' rx='5' style='' class='basic label-container'/%3e%3cg transform='translate(-29.796875%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='59.59375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eRequest%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(405.8359375%2c 43.515625)' id='flowchart-b-1' class='node default'%3e%3cpath transform='translate(-31.5234375%2c -32.072704611549646)' style='' class='basic label-container' d='M0%2c8.381803074366431 a31.5234375%2c8.381803074366431 0%2c0%2c0 63.046875%2c0 a31.5234375%2c8.381803074366431 0%2c0%2c0 -63.046875%2c0 l0%2c47.38180307436643 a31.5234375%2c8.381803074366431 0%2c0%2c0 63.046875%2c0 l0%2c-47.38180307436643'/%3e%3cg transform='translate(-24.0234375%2c -2)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='48.046875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eQueue%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(219.0546875%2c 96.30978965759277)' id='flowchart-c-2' class='node default'%3e%3cpolygon transform='translate(-51.9609375%2c19.5)' class='label-container' points='-19.5%2c0 103.921875%2c0 123.421875%2c-39 0%2c-39'/%3e%3cg transform='translate(-44.4609375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='88.921875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3e!capacityFull%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(522.875%2c 43.515625)' id='flowchart-p-3' class='node default'%3e%3ccircle cy='0' cx='0' r='35.515625' style='' class='basic label-container'/%3e%3cg transform='translate(-28.015625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='56.03125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eprocess%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(405.8359375%2c 149.10395431518555)' id='flowchart-d-4' class='node default'%3e%3ccircle cy='0' cx='0' r='23.515625' style='' class='basic label-container'/%3e%3cg transform='translate(-16.015625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='32.03125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3edrop%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Leaky and Token bucket algorithm are relatively simple to implement but on the downside it’s difficult to find the right value for bucket size and token generation/request consumption rate.
Fixed Window Counter
In fixed window counter we keep track of number of requests within a fixed time range e.g. a minute or 30 seconds etc. We only process a limited number of requests within the time window beyond which the requests are dropped (red ones).
%3b%7d%23mermaid-2 .section2%7bfill:%23fff400%3b%7d%23mermaid-2 .section1%2c%23mermaid-2 .section3%7bfill:white%3bopacity:0.2%3b%7d%23mermaid-2 .sectionTitle0%7bfill:%23333%3b%7d%23mermaid-2 .sectionTitle1%7bfill:%23333%3b%7d%23mermaid-2 .sectionTitle2%7bfill:%23333%3b%7d%23mermaid-2 .sectionTitle3%7bfill:%23333%3b%7d%23mermaid-2 .sectionTitle%7btext-anchor:start%3bfont-family:arial%2csans-serif%3b%7d%23mermaid-2 .grid .tick%7bstroke:lightgrey%3bopacity:0.8%3bshape-rendering:crispEdges%3b%7d%23mermaid-2 .grid .tick text%7bfont-family:arial%2csans-serif%3bfill:%23333%3b%7d%23mermaid-2 .grid path%7bstroke-width:0%3b%7d%23mermaid-2 .today%7bfill:none%3bstroke:red%3bstroke-width:2px%3b%7d%23mermaid-2 .task%7bstroke-width:2%3b%7d%23mermaid-2 .taskText%7btext-anchor:middle%3bfont-family:arial%2csans-serif%3b%7d%23mermaid-2 .taskTextOutsideRight%7bfill:black%3btext-anchor:start%3bfont-family:arial%2csans-serif%3b%7d%23mermaid-2 .taskTextOutsideLeft%7bfill:black%3btext-anchor:end%3b%7d%23mermaid-2 .task.clickable%7bcursor:pointer%3b%7d%23mermaid-2 .taskText.clickable%7bcursor:pointer%3bfill:%23003163!important%3bfont-weight:bold%3b%7d%23mermaid-2 .taskTextOutsideLeft.clickable%7bcursor:pointer%3bfill:%23003163!important%3bfont-weight:bold%3b%7d%23mermaid-2 .taskTextOutsideRight.clickable%7bcursor:pointer%3bfill:%23003163!important%3bfont-weight:bold%3b%7d%23mermaid-2 .taskText0%2c%23mermaid-2 .taskText1%2c%23mermaid-2 .taskText2%2c%23mermaid-2 .taskText3%7bfill:white%3b%7d%23mermaid-2 .task0%2c%23mermaid-2 .task1%2c%23mermaid-2 .task2%2c%23mermaid-2 .task3%7bfill:%238a90dd%3bstroke:%23534fbc%3b%7d%23mermaid-2 .taskTextOutside0%2c%23mermaid-2 .taskTextOutside2%7bfill:black%3b%7d%23mermaid-2 .taskTextOutside1%2c%23mermaid-2 .taskTextOutside3%7bfill:black%3b%7d%23mermaid-2 .active0%2c%23mermaid-2 .active1%2c%23mermaid-2 .active2%2c%23mermaid-2 .active3%7bfill:%23bfc7ff%3bstroke:%23534fbc%3b%7d%23mermaid-2 .activeText0%2c%23mermaid-2 .activeText1%2c%23mermaid-2 .activeText2%2c%23mermaid-2 .activeText3%7bfill:black!important%3b%7d%23mermaid-2 .done0%2c%23mermaid-2 .done1%2c%23mermaid-2 .done2%2c%23mermaid-2 .done3%7bstroke:grey%3bfill:lightgrey%3bstroke-width:2%3b%7d%23mermaid-2 .doneText0%2c%23mermaid-2 .doneText1%2c%23mermaid-2 .doneText2%2c%23mermaid-2 .doneText3%7bfill:black!important%3b%7d%23mermaid-2 .crit0%2c%23mermaid-2 .crit1%2c%23mermaid-2 .crit2%2c%23mermaid-2 .crit3%7bstroke:%23ff8888%3bfill:red%3bstroke-width:2%3b%7d%23mermaid-2 .activeCrit0%2c%23mermaid-2 .activeCrit1%2c%23mermaid-2 .activeCrit2%2c%23mermaid-2 .activeCrit3%7bstroke:%23ff8888%3bfill:%23bfc7ff%3bstroke-width:2%3b%7d%23mermaid-2 .doneCrit0%2c%23mermaid-2 .doneCrit1%2c%23mermaid-2 .doneCrit2%2c%23mermaid-2 .doneCrit3%7bstroke:%23ff8888%3bfill:lightgrey%3bstroke-width:2%3bcursor:pointer%3bshape-rendering:crispEdges%3b%7d%23mermaid-2 .milestone%7btransform:rotate(45deg) scale(0.8%2c0.8)%3b%7d%23mermaid-2 .milestoneText%7bfont-style:italic%3b%7d%23mermaid-2 .doneCritText0%2c%23mermaid-2 .doneCritText1%2c%23mermaid-2 .doneCritText2%2c%23mermaid-2 .doneCritText3%7bfill:black!important%3b%7d%23mermaid-2 .vert%7bstroke:navy%3b%7d%23mermaid-2 .vertText%7bfont-size:15px%3btext-anchor:middle%3bfill:navy!important%3b%7d%23mermaid-2 .activeCritText0%2c%23mermaid-2 .activeCritText1%2c%23mermaid-2 .activeCritText2%2c%23mermaid-2 .activeCritText3%7bfill:black!important%3b%7d%23mermaid-2 .titleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3bfont-family:arial%2csans-serif%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cg text-anchor='middle' font-family='sans-serif' font-size='10' fill='none' transform='translate(75%2c 170)' class='grid'%3e%3cpath d='M0.5%2c-135V0.5H1114.5V-135' stroke='currentColor' class='domain'/%3e%3cg transform='translate(0.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-135' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:00%3c/text%3e%3c/g%3e%3cg transform='translate(203.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-135' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:10%3c/text%3e%3c/g%3e%3cg transform='translate(405.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-135' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:20%3c/text%3e%3c/g%3e%3cg transform='translate(608.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-135' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:30%3c/text%3e%3c/g%3e%3cg transform='translate(810.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-135' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:40%3c/text%3e%3c/g%3e%3cg transform='translate(1013.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-135' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:50%3c/text%3e%3c/g%3e%3c/g%3e%3cg%3e%3crect class='section section0' height='24' width='1226.5' y='48' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='72' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='96' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='120' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='144' x='0'/%3e%3c/g%3e%3cg%3e%3crect class='task task0' transform-origin='176.5px 60px' height='20' width='203' y='50' x='75' ry='3' rx='3' id='task1'/%3e%3crect class='task task0' transform-origin='379px 84px' height='20' width='202' y='74' x='278' ry='3' rx='3' id='task2'/%3e%3crect class='task task0' transform-origin='682.5px 108px' height='20' width='203' y='98' x='581' ry='3' rx='3' id='task3'/%3e%3crect class='task crit0' transform-origin='986.5px 132px' height='20' width='203' y='122' x='885' ry='3' rx='3' id='task4'/%3e%3crect class='task crit0' transform-origin='1087.5px 156px' height='20' width='203' y='146' x='986' ry='3' rx='3' id='task5'/%3e%3ctext class='taskText taskText0 width-14.0625' y='63.5' x='176.5' font-size='11' id='task1-text'%3eR1 %3c/text%3e%3ctext class='taskText taskText0 width-14.0625' y='87.5' x='379' font-size='11' id='task2-text'%3eR2 %3c/text%3e%3ctext class='taskText taskText0 width-14.0625' y='111.5' x='682.5' font-size='11' id='task3-text'%3eR3 %3c/text%3e%3ctext class='taskText taskText0 critText0 width-14.0625' y='135.5' x='986.5' font-size='11' id='task4-text'%3eR4 %3c/text%3e%3ctext class='taskText taskText0 critText0 width-14.0625' y='159.5' x='1087.5' font-size='11' id='task5-text'%3eR5 %3c/text%3e%3c/g%3e%3cg%3e%3ctext class='sectionTitle sectionTitle0' font-size='11' y='110' x='10' dy='0em'%3e%3ctspan x='10' alignment-baseline='central'/%3e%3c/text%3e%3c/g%3e%3cg class='today'%3e%3cline class='today' y2='195' y1='25' x2='671574' x1='671574'/%3e%3c/g%3e%3ctext class='titleText' y='25' x='632'%3eRequests v/s Time%3c/text%3e%3c/svg%3e)
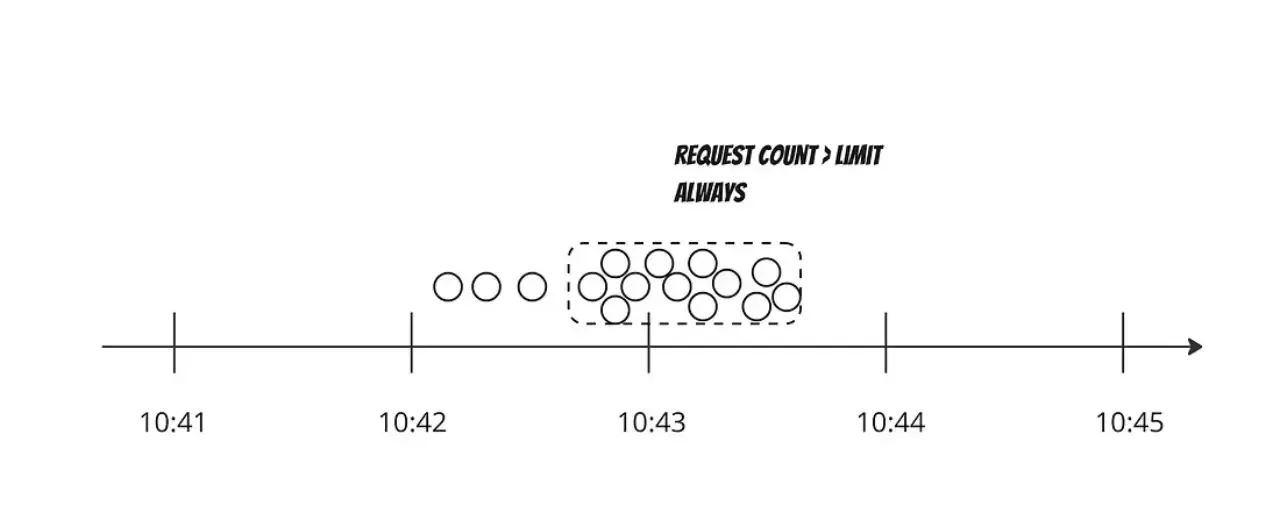
The issue with fixed window counter comes around when there are requests coming near the boundary of two windows. In such a scenario we actually end up processing more request within time window than set parameter.
%3b%7d%23mermaid-3 .section2%7bfill:%23fff400%3b%7d%23mermaid-3 .section1%2c%23mermaid-3 .section3%7bfill:white%3bopacity:0.2%3b%7d%23mermaid-3 .sectionTitle0%7bfill:%23333%3b%7d%23mermaid-3 .sectionTitle1%7bfill:%23333%3b%7d%23mermaid-3 .sectionTitle2%7bfill:%23333%3b%7d%23mermaid-3 .sectionTitle3%7bfill:%23333%3b%7d%23mermaid-3 .sectionTitle%7btext-anchor:start%3bfont-family:arial%2csans-serif%3b%7d%23mermaid-3 .grid .tick%7bstroke:lightgrey%3bopacity:0.8%3bshape-rendering:crispEdges%3b%7d%23mermaid-3 .grid .tick text%7bfont-family:arial%2csans-serif%3bfill:%23333%3b%7d%23mermaid-3 .grid path%7bstroke-width:0%3b%7d%23mermaid-3 .today%7bfill:none%3bstroke:red%3bstroke-width:2px%3b%7d%23mermaid-3 .task%7bstroke-width:2%3b%7d%23mermaid-3 .taskText%7btext-anchor:middle%3bfont-family:arial%2csans-serif%3b%7d%23mermaid-3 .taskTextOutsideRight%7bfill:black%3btext-anchor:start%3bfont-family:arial%2csans-serif%3b%7d%23mermaid-3 .taskTextOutsideLeft%7bfill:black%3btext-anchor:end%3b%7d%23mermaid-3 .task.clickable%7bcursor:pointer%3b%7d%23mermaid-3 .taskText.clickable%7bcursor:pointer%3bfill:%23003163!important%3bfont-weight:bold%3b%7d%23mermaid-3 .taskTextOutsideLeft.clickable%7bcursor:pointer%3bfill:%23003163!important%3bfont-weight:bold%3b%7d%23mermaid-3 .taskTextOutsideRight.clickable%7bcursor:pointer%3bfill:%23003163!important%3bfont-weight:bold%3b%7d%23mermaid-3 .taskText0%2c%23mermaid-3 .taskText1%2c%23mermaid-3 .taskText2%2c%23mermaid-3 .taskText3%7bfill:white%3b%7d%23mermaid-3 .task0%2c%23mermaid-3 .task1%2c%23mermaid-3 .task2%2c%23mermaid-3 .task3%7bfill:%238a90dd%3bstroke:%23534fbc%3b%7d%23mermaid-3 .taskTextOutside0%2c%23mermaid-3 .taskTextOutside2%7bfill:black%3b%7d%23mermaid-3 .taskTextOutside1%2c%23mermaid-3 .taskTextOutside3%7bfill:black%3b%7d%23mermaid-3 .active0%2c%23mermaid-3 .active1%2c%23mermaid-3 .active2%2c%23mermaid-3 .active3%7bfill:%23bfc7ff%3bstroke:%23534fbc%3b%7d%23mermaid-3 .activeText0%2c%23mermaid-3 .activeText1%2c%23mermaid-3 .activeText2%2c%23mermaid-3 .activeText3%7bfill:black!important%3b%7d%23mermaid-3 .done0%2c%23mermaid-3 .done1%2c%23mermaid-3 .done2%2c%23mermaid-3 .done3%7bstroke:grey%3bfill:lightgrey%3bstroke-width:2%3b%7d%23mermaid-3 .doneText0%2c%23mermaid-3 .doneText1%2c%23mermaid-3 .doneText2%2c%23mermaid-3 .doneText3%7bfill:black!important%3b%7d%23mermaid-3 .crit0%2c%23mermaid-3 .crit1%2c%23mermaid-3 .crit2%2c%23mermaid-3 .crit3%7bstroke:%23ff8888%3bfill:red%3bstroke-width:2%3b%7d%23mermaid-3 .activeCrit0%2c%23mermaid-3 .activeCrit1%2c%23mermaid-3 .activeCrit2%2c%23mermaid-3 .activeCrit3%7bstroke:%23ff8888%3bfill:%23bfc7ff%3bstroke-width:2%3b%7d%23mermaid-3 .doneCrit0%2c%23mermaid-3 .doneCrit1%2c%23mermaid-3 .doneCrit2%2c%23mermaid-3 .doneCrit3%7bstroke:%23ff8888%3bfill:lightgrey%3bstroke-width:2%3bcursor:pointer%3bshape-rendering:crispEdges%3b%7d%23mermaid-3 .milestone%7btransform:rotate(45deg) scale(0.8%2c0.8)%3b%7d%23mermaid-3 .milestoneText%7bfont-style:italic%3b%7d%23mermaid-3 .doneCritText0%2c%23mermaid-3 .doneCritText1%2c%23mermaid-3 .doneCritText2%2c%23mermaid-3 .doneCritText3%7bfill:black!important%3b%7d%23mermaid-3 .vert%7bstroke:navy%3b%7d%23mermaid-3 .vertText%7bfont-size:15px%3btext-anchor:middle%3bfill:navy!important%3b%7d%23mermaid-3 .activeCritText0%2c%23mermaid-3 .activeCritText1%2c%23mermaid-3 .activeCritText2%2c%23mermaid-3 .activeCritText3%7bfill:black!important%3b%7d%23mermaid-3 .titleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3bfont-family:arial%2csans-serif%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cg text-anchor='middle' font-family='sans-serif' font-size='10' fill='none' transform='translate(75%2c 194)' class='grid'%3e%3cpath d='M0.5%2c-159V0.5H1114.5V-159' stroke='currentColor' class='domain'/%3e%3cg transform='translate(0.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-159' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:30%3c/text%3e%3c/g%3e%3cg transform='translate(186.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-159' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:40%3c/text%3e%3c/g%3e%3cg transform='translate(371.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-159' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e00:50%3c/text%3e%3c/g%3e%3cg transform='translate(557.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-159' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e01:00%3c/text%3e%3c/g%3e%3cg transform='translate(743.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-159' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e01:10%3c/text%3e%3c/g%3e%3cg transform='translate(928.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-159' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e01:20%3c/text%3e%3c/g%3e%3cg transform='translate(1114.5%2c0)' opacity='1' class='tick'%3e%3cline y2='-159' stroke='currentColor'/%3e%3ctext style='text-anchor: middle%3b' font-size='10' stroke='none' dy='1em' y='3' fill='black'%3e01:30%3c/text%3e%3c/g%3e%3c/g%3e%3cg%3e%3crect class='section section0' height='24' width='1226.5' y='48' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='72' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='96' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='120' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='144' x='0'/%3e%3crect class='section section0' height='24' width='1226.5' y='168' x='0'/%3e%3c/g%3e%3cg%3e%3crect class='task task0' transform-origin='168px 60px' height='20' width='186' y='50' x='75' ry='3' rx='3' id='task1'/%3e%3crect class='task task0' transform-origin='353.5px 84px' height='20' width='185' y='74' x='261' ry='3' rx='3' id='task2'/%3e%3crect class='task task0' transform-origin='446.5px 108px' height='20' width='185' y='98' x='354' ry='3' rx='3' id='task3'/%3e%3crect class='task task0' transform-origin='725px 132px' height='20' width='186' y='122' x='632' ry='3' rx='3' id='task4'/%3e%3crect class='task task0' transform-origin='725px 156px' height='20' width='186' y='146' x='632' ry='3' rx='3' id='task5'/%3e%3crect class='task task0' transform-origin='1096px 180px' height='20' width='186' y='170' x='1003' ry='3' rx='3' id='task6'/%3e%3ctext class='taskText taskText0 width-14.0625' y='63.5' x='168' font-size='11' id='task1-text'%3eR3 %3c/text%3e%3ctext class='taskText taskText0 width-14.0625' y='87.5' x='353.5' font-size='11' id='task2-text'%3eR4 %3c/text%3e%3ctext class='taskText taskText0 width-14.0625' y='111.5' x='446.5' font-size='11' id='task3-text'%3eR5 %3c/text%3e%3ctext class='taskText taskText0 width-14.0625' y='135.5' x='725' font-size='11' id='task4-text'%3eR6 %3c/text%3e%3ctext class='taskText taskText0 width-14.0625' y='159.5' x='725' font-size='11' id='task5-text'%3eR7 %3c/text%3e%3ctext class='taskText taskText0 width-14.0625' y='183.5' x='1096' font-size='11' id='task6-text'%3eR8 %3c/text%3e%3c/g%3e%3cg%3e%3ctext class='sectionTitle sectionTitle0' font-size='11' y='122' x='10' dy='0em'%3e%3ctspan x='10' alignment-baseline='central'/%3e%3c/text%3e%3c/g%3e%3cg class='today'%3e%3cline class='today' y2='219' y1='25' x2='615060' x1='615060'/%3e%3c/g%3e%3ctext class='titleText' y='25' x='632'%3eRequests v/s Time%3c/text%3e%3c/svg%3e)
In the above example within time range of 00:30 - 01:30 instead of 3 the rate limiter allowed 6 requests which is double of what was expected of it to allow in a minute. O(2*n)
Sliding Window Log
Sliding Window log is a dynamic one which handles the previous faults in fixed window counter by keeping track of requests in the current time window which is updated with every new request. It also uses a log to keep track of current requests.
Whenever a new request arrives
- We delete all the entries older than current time window.
- Now request’s timestamp is added to our log which now represents all the requests made in current time window.
- If the
len(log) <= ratethen we process the request else its dropped
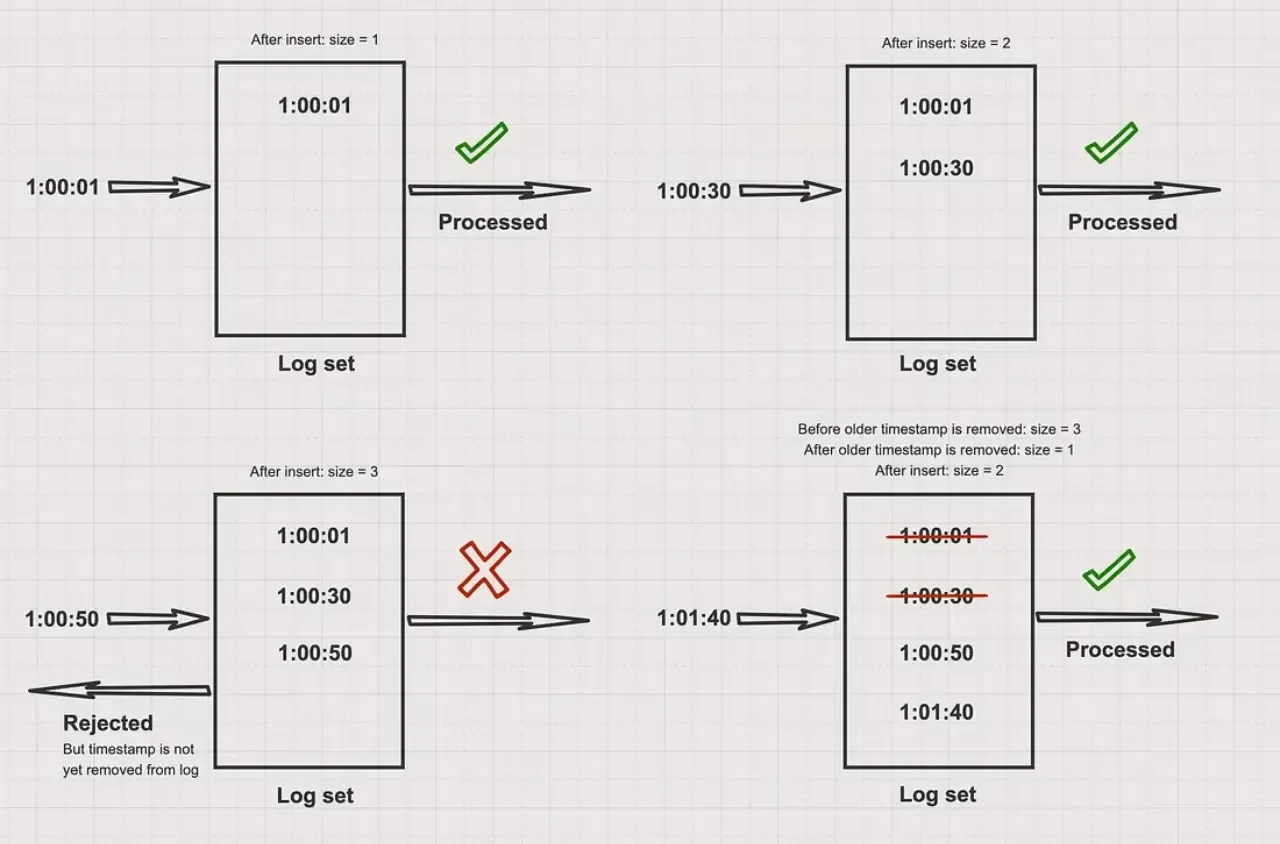
Generally redis sorted sets are the used to keep track of timestamps in an efficient data structure which allows easy querying and updates.
Even with all its goodness its a little flawed due to the high memory usage. In case of a DoS attack we can have thousands of these log entries leading to huge memory usage and no valid requests will be processed in this duration these drawbacks lead us to the last algorithm.
Sliding Window Counter
It is a hybrid approach inspired from fixed window counter and sliding window log. It takes the best part of both and combines them sliding window log + fixed window counter.
To fix the flaws of fixed window counter it uses a weighted counter to smooth out burst around window boundaries which takes previous and present window requests into account.
percent = (cur_time - start_time_cur_window) / window_size
weighted_counter = requests_prev_window * (1.0 - percent) + requests_cur_window * percentLiked sliding window log we need to use memory for keeping track of history. To count requests from each sender we will use multiple fixed time windows 1/60th the size of our rate limit’s time window like figma does. This remedies the memory footprint issue limiting it to just 60 values for every user.
4 bytes per counter * 60 counters * 100,000 users = 24,000,000 bytes OR 24MBTo reduce our memory footprint, we can store counters in a Redis hash which are highly efficient in their storage usage. Each new request which increments the counter it can set the expiry for it based on our time window but still there is a possibility of DoS attack to remedy this we should clean up hashes at regular intervals if they are rapidly increasing.
%3btext-align:center%3b%7d%23mermaid-4 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-4 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-4 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-4 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-4 .cluster text%7bfill:%23333%3b%7d%23mermaid-4 .cluster span%7bcolor:%23333%3b%7d%23mermaid-4 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-4 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-4 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-4 .icon-shape%2c%23mermaid-4 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-4 .icon-shape p%2c%23mermaid-4 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-4 .icon-shape rect%2c%23mermaid-4 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-4 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-4 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-4 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-4_flowchart-v2-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-4_flowchart-v2-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-4_flowchart-v2-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-4_flowchart-v2-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-4_flowchart-v2-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-4_flowchart-v2-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_r_i_0' d='M121.375%2c155.693L125.542%2c155.693C129.708%2c155.693%2c138.042%2c155.693%2c145.708%2c155.693C153.375%2c155.693%2c160.375%2c155.693%2c163.875%2c155.693L167.375%2c155.693'/%3e%3cpath marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_i_c_0' d='M329.438%2c155.693L333.604%2c155.693C337.771%2c155.693%2c346.104%2c155.693%2c355.479%2c155.767C364.854%2c155.841%2c375.271%2c155.989%2c380.48%2c156.063L385.688%2c156.136'/%3e%3cpath marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)' marker-start='url(%23mermaid-4_flowchart-v2-pointStart)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_c_re_0' d='M517.018%2c134.078L535.343%2c118.247C553.668%2c102.415%2c590.318%2c70.752%2c613.404%2c54.92C636.49%2c39.089%2c646.01%2c39.089%2c650.771%2c39.089L655.531%2c39.089'/%3e%3cpath marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_c_p_0' d='M592.719%2c156.193L598.427%2c156.11C604.135%2c156.027%2c615.552%2c155.86%2c624.76%2c155.777C633.969%2c155.693%2c640.969%2c155.693%2c644.469%2c155.693L647.969%2c155.693'/%3e%3cpath marker-end='url(%23mermaid-4_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_c_d_0' d='M514.819%2c175.693L533.511%2c191.112C552.202%2c206.532%2c589.586%2c237.37%2c612.527%2c252.79C635.469%2c268.209%2c643.969%2c268.209%2c648.219%2c268.209L652.469%2c268.209'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(64.6875%2c 155.69321060180664)' id='flowchart-r-0' class='node default'%3e%3crect height='54' width='113.375' y='-27' x='-56.6875' style='' class='basic label-container'/%3e%3cg transform='translate(-26.6875%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='53.375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3erequest%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(250.40625%2c 155.69321060180664)' id='flowchart-i-1' class='node default'%3e%3crect height='54' width='158.0625' y='-27' x='-79.03125' ry='5' rx='5' style='' class='basic label-container'/%3e%3cg transform='translate(-64.03125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='128.0625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eincrement counter%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(490.703125%2c 155.69321060180664)' id='flowchart-c-2' class='node default'%3e%3cpolygon transform='translate(-91.765625%2c19.5)' class='label-container' points='-19.5%2c0 183.53125%2c0 203.03125%2c-39 0%2c-39'/%3e%3cg transform='translate(-84.265625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='168.53125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eweighted counter %26lt%3b limit%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(687.484375%2c 39.08879280090332)' id='flowchart-re-3' class='node default'%3e%3cpath transform='translate(-27.953125%2c -31.088789082743133)' style='' class='basic label-container' d='M0%2c7.725859388495422 a27.953125%2c7.725859388495422 0%2c0%2c0 55.90625%2c0 a27.953125%2c7.725859388495422 0%2c0%2c0 -55.90625%2c0 l0%2c46.72585938849542 a27.953125%2c7.725859388495422 0%2c0%2c0 55.90625%2c0 l0%2c-46.72585938849542'/%3e%3cg transform='translate(-20.453125%2c -2)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='40.90625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eRedis%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(687.484375%2c 155.69321060180664)' id='flowchart-p-4' class='node default'%3e%3ccircle cy='0' cx='0' r='35.515625' style='' class='basic label-container'/%3e%3cg transform='translate(-28.015625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='56.03125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eprocess%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(687.484375%2c 268.20883560180664)' id='flowchart-d-5' class='node default'%3e%3crect height='54' width='62.03125' y='-27' x='-31.015625' ry='5' rx='5' style='' class='basic label-container'/%3e%3cg transform='translate(-16.015625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='32.03125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3edrop%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
HTTP Response
Now that we have rate limited user its also important to convey it back to the end user. HTTP 429 - Too Many Requests is the status code which is created for this purpose. We can add in more details in HTTP Headers as well
- X-Ratelimit-Remaining
- X-Ratelimit-Limit
- X-Ratelimit-Retry-After

I wrote this blog to better my understanding as am currently reading the holy grail of system design: The System Design Interview Book. I was never rate limited before but recently when I unfollowed over 1k people on Instagram it rate limited me.
I made use of mermaid diagrams for the first time in my blog compared to using excalidraw. Mermaid is pretty cool, easy to use, keeps me inside the markdown and its just text so very easily transferable.
I hope I was able to share my understanding with you, thanks for your support till here. If you’ve enjoyed this read, please share it, to help others find it as well. Also, feel free ping me up for any comment on @1108King😁